
Recent earnings prints from Amazon.com Inc. and Snowflake Inc., along with new survey data, have provided additional context on top of the two events that Snowflake and Databricks Inc. each hosted last June. Specifically, we believe that the effects of cloud optimization are still being felt but are nearing the end of peak negative impact on cloud companies.
Snowflake’s recent renewal with Microsoft Corp. better aligns sales incentives and should improve the company’s traction with Microsoft Azure, a platform that has long favored Databricks. Google LLC, however, remains a different story, as its agenda is to build out its own data cloud stack, rather than supporting Snowflake’s aspirations.
In this Breaking Analysis, we clarify some of our previous assumptions around Snowflake economics. We’ll dig into the three big U.S.-based hyperscale cloud platforms with Enterprise Technology Research data to better understand the footprint that key data platforms have in those cloud accounts. And ahead of next week’s Google Cloud Next conference, we’ll preview how we believe Google is evolving its cloud and data stacks to compete more effectively in the market.
Snowflake’s decelerating Net Score aligns with its earnings reports
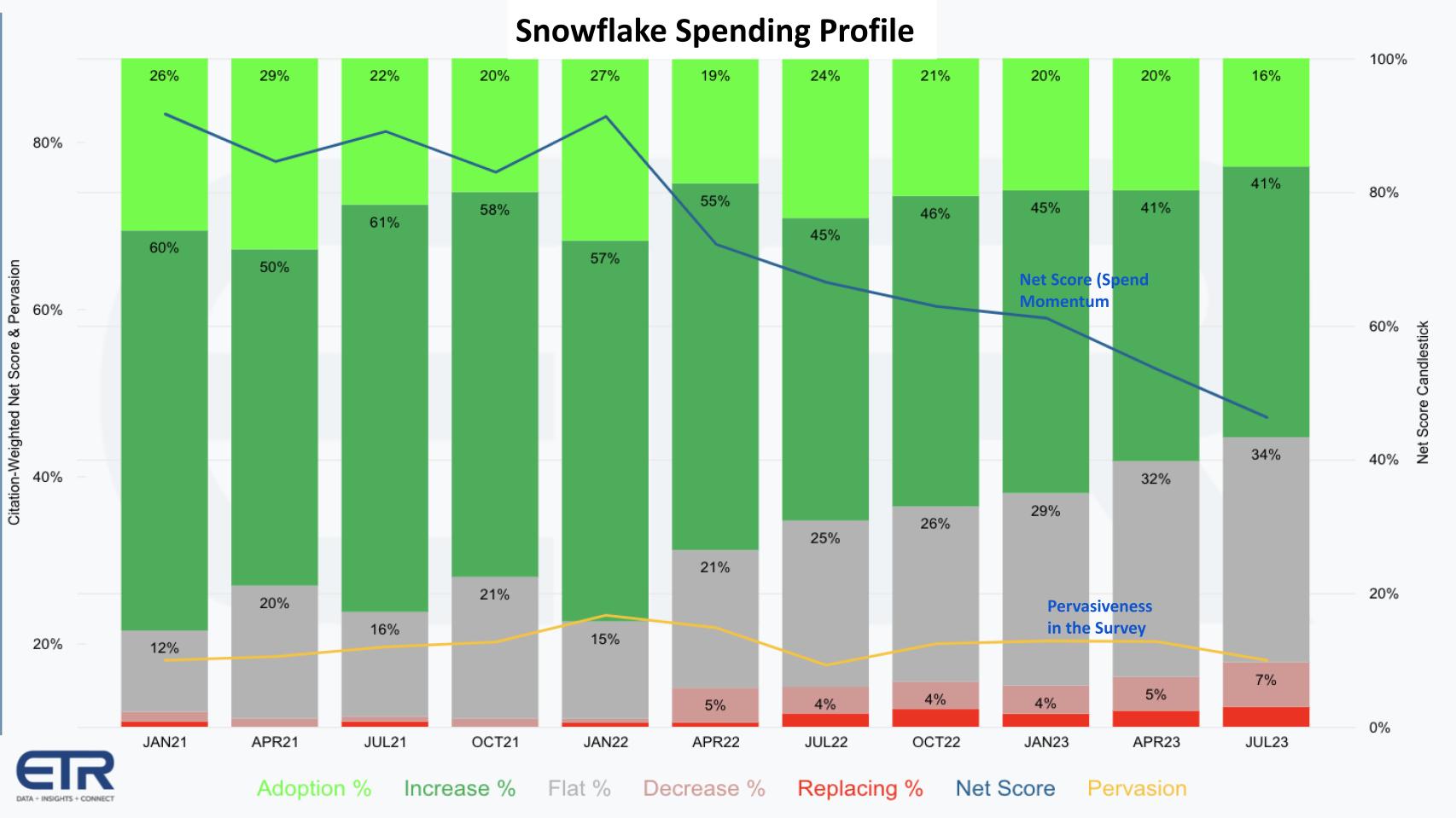
The chart above breaks down ETR’s proprietary spending methodology called Net Score. Net Score measures the net percent of customers spending more on a platform and is derived as follows: The lime green bars above represent new customer adds, which in the latest July 2023 survey represents 16% of the Snowflake respondents in the survey. The forest green represents the percentage of customers indicating their second-half spend on Snowflake will be up by 6% of more. The gray bar represents those customers indicating flat spending (+/- 5%). The pink area at 7% represents those customers where spending is down 6% or worse, and the red is defections.
Subtract the reds from the greens and you get Net Score, which is shown in that blue line above. Note that anything greater than 40% is still considered highly elevated. Nonetheless, the data has been informative and predictive for the last several quarters, indicating a deceleration in Snowflake’s momentum relative to its previous highs.
That yellow line above at the bottom of the chart is a measure of pervasiveness in the survey. It essentially takes the number of mentions of Snowflake in the survey divided by the total survey N of approximately 1,700 responses. The yellow line is flattening, which is a negative, but as you can see in the July 2022 data, these trends ebb and flow. However, this is something to watch as AI steals share from other initiatives and Snowflake ramps up total available market expansion with Snowpark, Streamlit and its own artificial intelligence initiatives.
Why is spending on Snowflake decelerating? A third scenario
Our initial thinking was that the steady decline has been a function of two main factors, including: 1) The macro economy as evidenced by the cumulative effects of the gray and red bars above (spending flat to down); and 2) The law of larger numbers – that is, the reduction in Snowflake’s momentum is a natural occurrence as the company became bigger.
But we began to formulate a third premise at Snowflake Summit as customers and partners told us that increasingly, firms are choosing to do their data engineering and data prep outside Snowflake because it’s less expensive. The logic is that doing this type of batch work inside Snowflake, an architecture designed for high performance, could be done more cheaply in Spark, such as Amazon EMR or Databricks, with supporting orchestration tools such as Apache Airflow or with dbt managing the whole process.
Moreover, we observed in the ETR data a high degree of overlap in Snowflake accounts also running Databricks and Amazon analytics where EMR likely could be found. Connecting these dots with the anecdotal information helped us formulate a thesis that some portion of Snowflake’s deceleration was coming from competitive data prep alternatives.
Snowpark performance challenges the third scenario
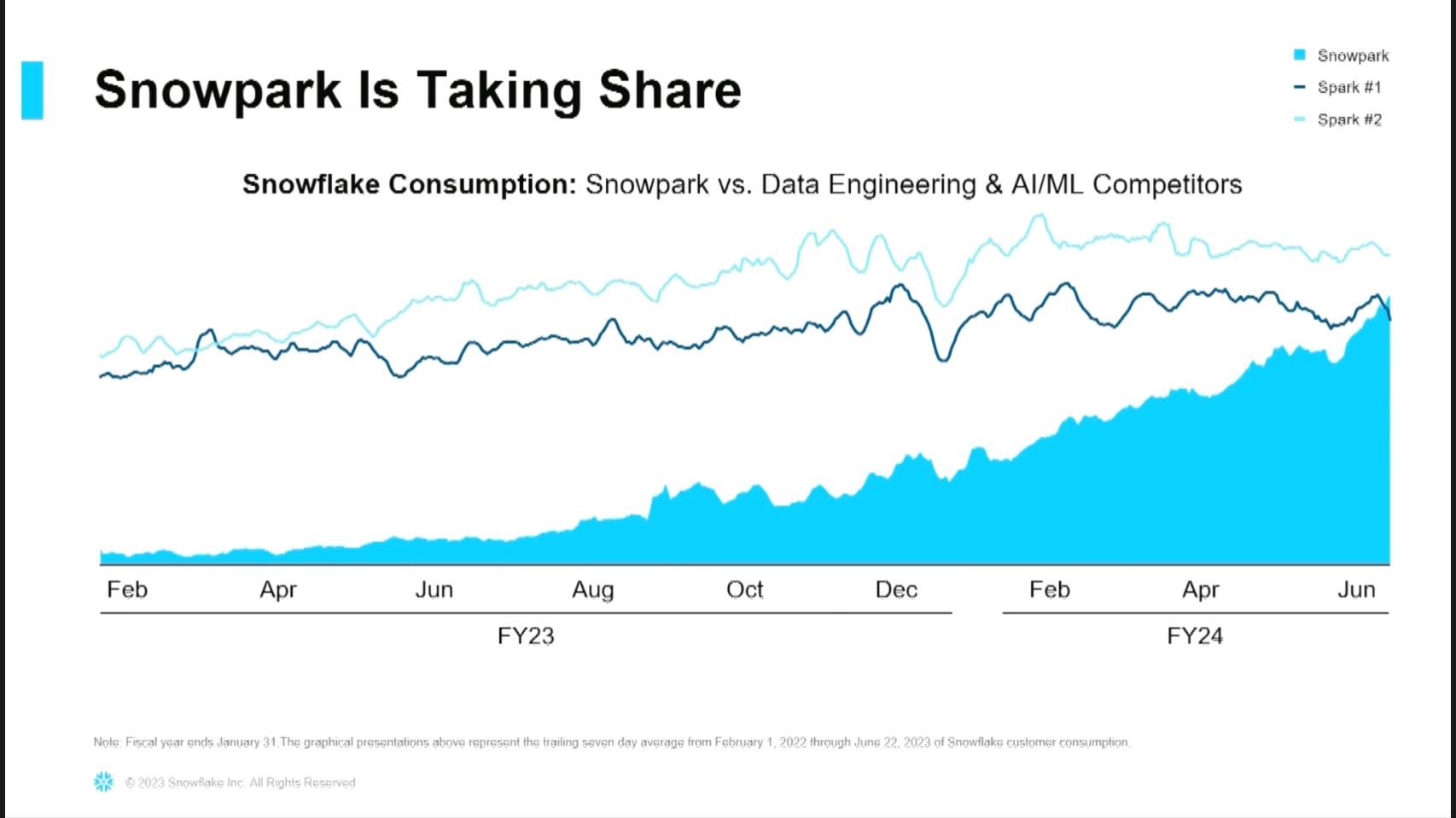
Snowflake shared data at its Financial Analyst Day that contradicts our original premise. Above is a chart that Chief Financial Officer Mike Scarpelli showed at that meeting. He explains the data as follows:
Snowpark is taking its share. What this graph is showing you is two Spark technologies that are running within our customer base. I can see that the blue at the bottom is Snowpark, and you can see how now Snowpark consumption, this is looking at daily credits, what they’re consuming is now outpacing Spark No. 1, and it’s going to surpass Spark No. 2. And so what you’re seeing also is, those ones we’re growing within our customer base, we’re growing much faster than them.
Snowpark is Snowflake’s framework that allows developers to do their work more efficiently inside Snowflake. At the same financial analyst meeting, Snowflake Senior Vice President of Product Christian Kleinerman shared data that using Snowpark’s DataFrames application programming interface, organizations were getting two to four times the performance of Spark. He explained that customers are seeing 10% to 100% lower costs relative to Spark, with one outlier customer achieving 1,200% better costs.
Watch Snowflake CFO Mike Scarpelli explain how Snowpark is taking share from Spark
In the diagram above, we infer Spark No. 1 is most likely EMR and Spark No. 2 is probably Databricks.
Late last week, we had a private meeting with Kleinerman to clarify this data and he explained in more detail why Snowpark was more cost-effective than Spark for doing this type of work. He expressed strong conviction that Snowflake is in a good position to capture the data engineering and data prep work going forward. He also assured us that this was an apples-to-apples comparison, meaning the cost data excluded data movement and assumed the data was already in a Spark platform.
Our takeaway is that if Snowflake customers have Snowpark, they’ll keep the data inside Snowflake.
What percentage of Snowflake customers have Snowpark?
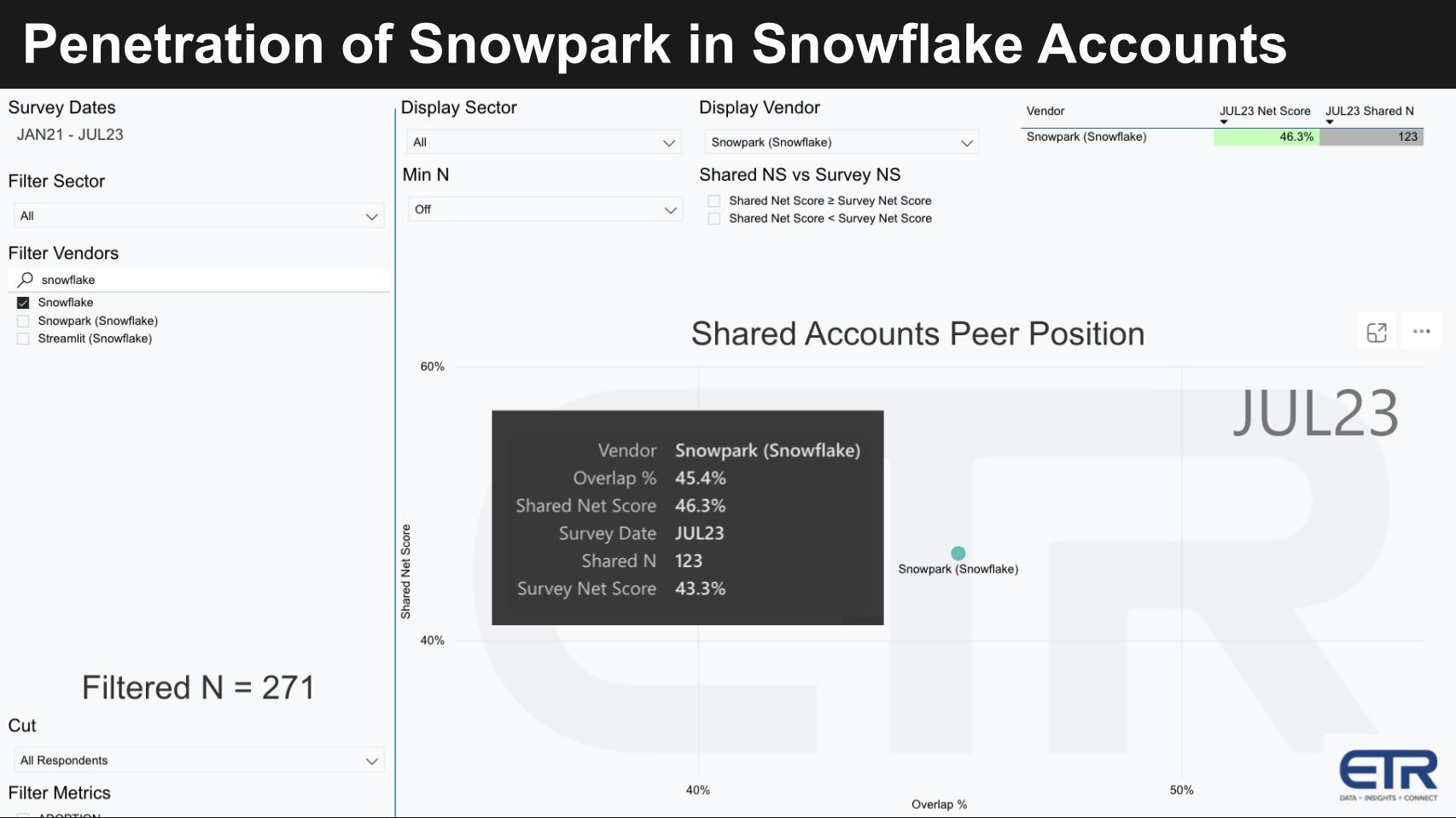
The power of the ETR platform is that we can answer questions like this with a few clicks. As shown in the graphic above, the ETR data shows that of the 271 Snowflake accounts in the dataset, nearly half (45%) also have Snowpark. Moreover, on its earnings call, Snowflake said that 63% of its G2000 customers are using Snowpark on a weekly basis.
63% of our Global 2000 customers are using Snowpark on a weekly basis — Snowflake CEO Frank Slootman, August 2023
Key takeaways and important questions that remain
- Snowflake needed Python programmability as an option for organizations that wanted to do data manipulation in something perhaps more expressive than SQL. They now have that capability. While adoption has been seemingly fast, half of Snowflake’s accounts still aren’t actively using the capability and so the third scenario could still be a headwind for Snowflake.
- The question that arises is: Are we seeing in the chart a replacement for the perceived lower-cost options of Amazon EMR or Databricks for batch work… or is it Snowflake customers using Python instead of SQL because of SQL’s inherent limitations? In other words, the data doesn’t definitively show that some customers aren’t doing those batch operations outside Snowflake.
- The cost savings are perhaps understated relative to the alternatives because in reality customers either have to extract the data or, in the case of data residing in Databricks, they’re running both Databricks compute and Snowflake compute, so it’s like doubly expensive. We don’t have the full picture yet.
- The real billion-dollar question is: Will customers, with the Snowpark option, consolidate their entire data estate, doing data engineering as well as the business intelligence dashboard serving all in Snowflake?
Snowflake has a compelling story now and an offering, but the marketing challenge is to convince customers to go “all in” and consolidate all data aligning with Snowflake’s grand vision.
Snowflake goes after big fish
Scarpelli has said his focus is not so much on booking new logos, rather his main interest is in identifying and nurturing customers that will consume $1 million or more annually with Snowflake. As such, the company’s penetration in Global 2000 is important.
As a side note, Slootman has emphasized to us that Snowflake has created a separate sales organization and process to go after new logos, so adding new names is vital for future growth. But it’s not what drives near-term revenue, as customers generally start small.
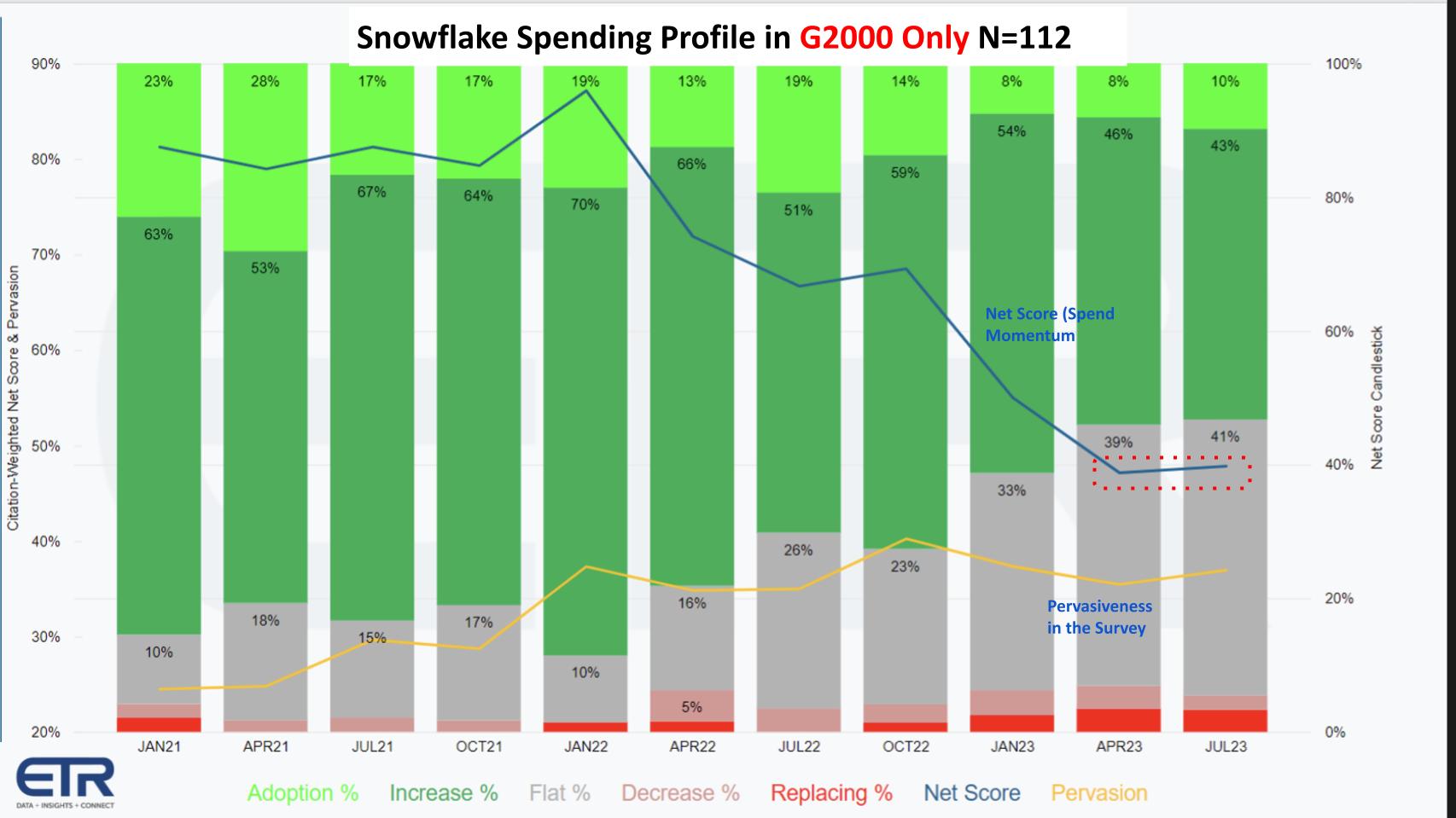
The graphic above shows the same Net Score granularity and sequential performance (blue line) and the penetration in the ETR data set (yellow line) isolated within Global 2000 accounts (N=112). Note that the survey is forward-looking and asks customers about spending intention in upcoming periods.
The red dotted area that’s highlighted on the blue line suggests that the deceleration trend within Snowflake’s largest customers is reversing, albeit slowly. But it’s a positive sign since the ETR methodology is based on number of customers, not spending volume. So a small reversal in the largest accounts in the latter part of this year will flow to top-line results if this data proves to be accurate.
Snowflake’s multicloud expansion agenda
Most of Snowflake’s business is on AWS. Despite what we refer to as a supercloud, Snowflake is only just getting ramped up in Azure and faces significant headwinds in Google Cloud. In particular, prior to its OpenAI relationship, Microsoft has relied extensively on its Databricks partnership and has competed with Snowflake, despite Snowflake’s committed spend on Azure.
Slootman has been transparent and vocal about the historic tension with Microsoft. Specifically, he has said in conversations with Microsoft CEO Satya Nadella that when Snowflake wins a deal, Microsoft will come back to the account and try to unhook the deal with millions of dollars in free services. And Microsoft is leading with Databricks as a first-party product. Slootman told Nadella if we’re going to renew our commitment with Azure, this type of behavior has to stop.
At the financial analyst day in June at Snowflake Summit, Snowflake showed a video of Slootman interviewing Nadella about this very issue. It was an important piece of evidence to try to convince investors that the financial commitment Snowflake just renewed for Microsoft Azure will pay requisite dividends.
Snowflake in AWS accounts
Snowflake does well in Amazon accounts because its product is simpler and more functional than Amazon’s bespoke analytics offerings comprising Red Shift and Amazon’s data lake, among other AWS and ecosystem tooling. The following ETR data shows the presence of key data platforms within AWS accounts.
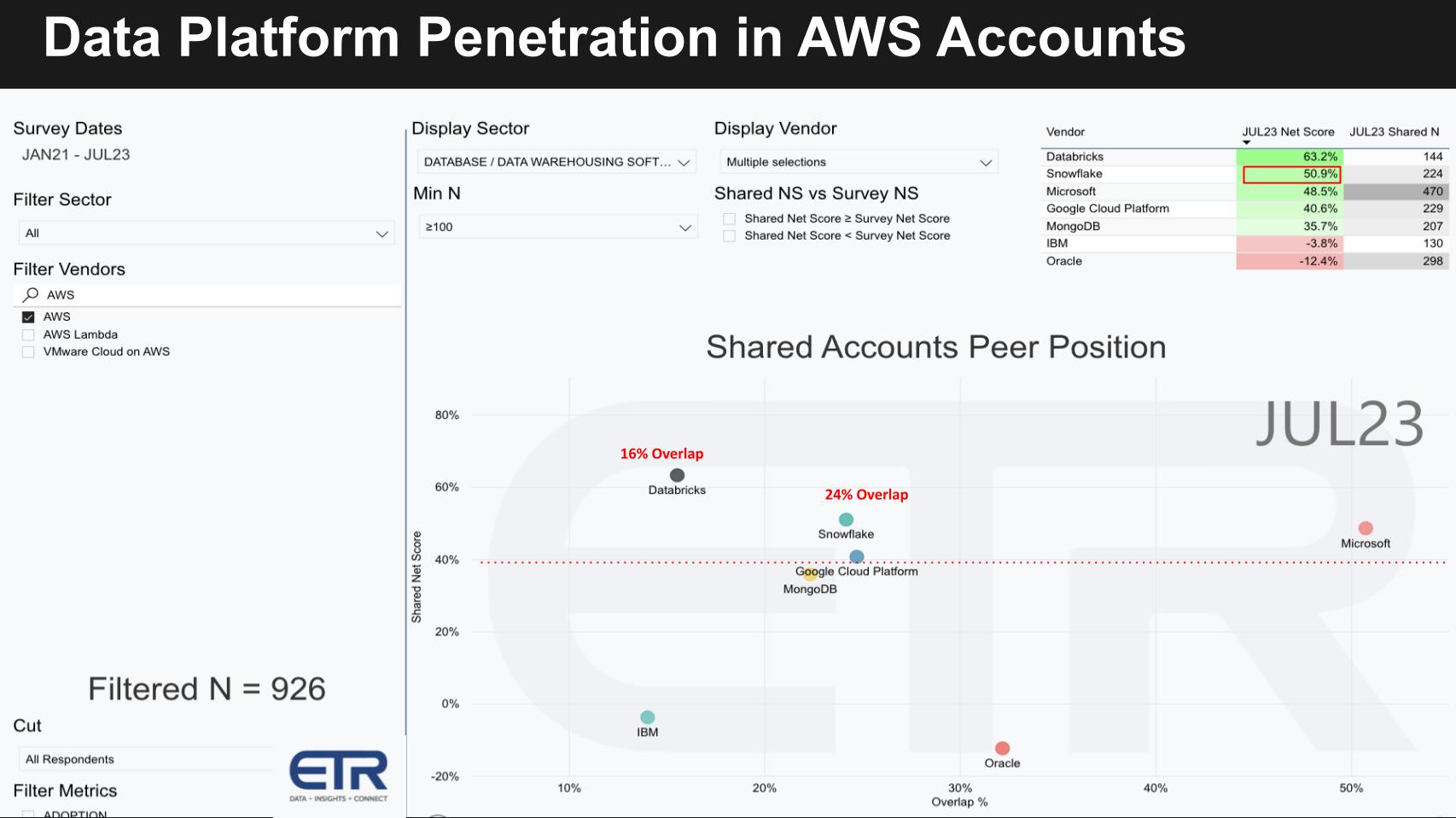
The graph filters 926 AWS accounts (lower left N) and plots the Net Score or spending momentum on the Y axis against the penetration of key data platforms within AWS accounts. The red dotted line at 40% indicates a highly elevated Net Score.
Note: This data is not representative of platforms running on AWS. Rather it represents the account overlap of these platforms in AWS accounts. Also note that these include all data platforms, including on-premises databases if they exist.
As you can see, there’s a 24% and 16% overlap in AWS accounts with Snowflake and Databricks, respectively.
In the upper right table we show the Net Score and the N in the data cut. Snowflake has a 51% Net Score, second only to Databricks impressive 63%, with an N of 224 and 144, respectively.
We’ve also plotted other data platforms from Microsoft, Google Cloud, Oracle, MongoDB Inc. and IBM Corp.
Snowflake in Azure accounts
The slide below shows the same data within 993 Azure accounts (see N in the bottom left).
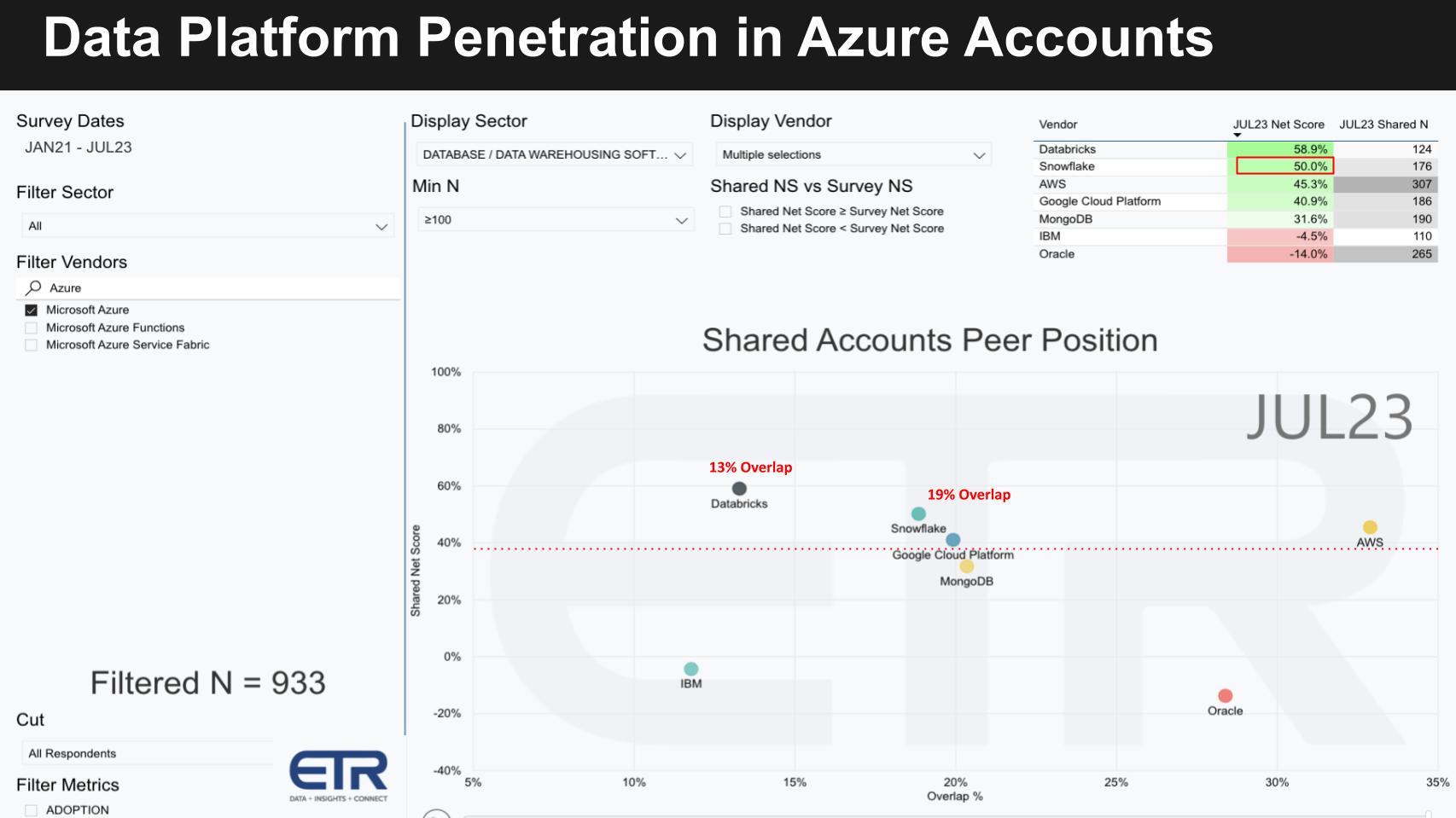
Note the Snowflake and Databricks overlap in these accounts is 19% and 13%, respectively, lower than their positions in AWS accounts. As well, in the upper right table you can see Snowflake has a Net Score of 50% with Databricks at 59%. Their respective Ns are 176 and 124, suggesting that Databricks has a higher penetration relative to Snowflake in Azure accounts than it does in AWS accounts.
Snowflake in Google Cloud accounts
Google is a different animal altogether. Google has aspirations in data and AI platforms that make it much more competitive with both Snowflake and Databricks.
Note in the chart below that we filter the data on 489 Google Cloud accounts (lower left N). The Snowflake and Databricks overlap more closely resembles their respective presence in AWS accounts. But not surprisingly, their Net Scores drop considerably – Snowflake’s to 38% and Databricks’ to 49%. The lower Ns are more a function of Google Cloud’s smaller market presence and are not really indicative, although the presence of Databricks relative to Snowflake is even higher, underscoring the headwinds Snowflake faces inside Google Cloud accounts.
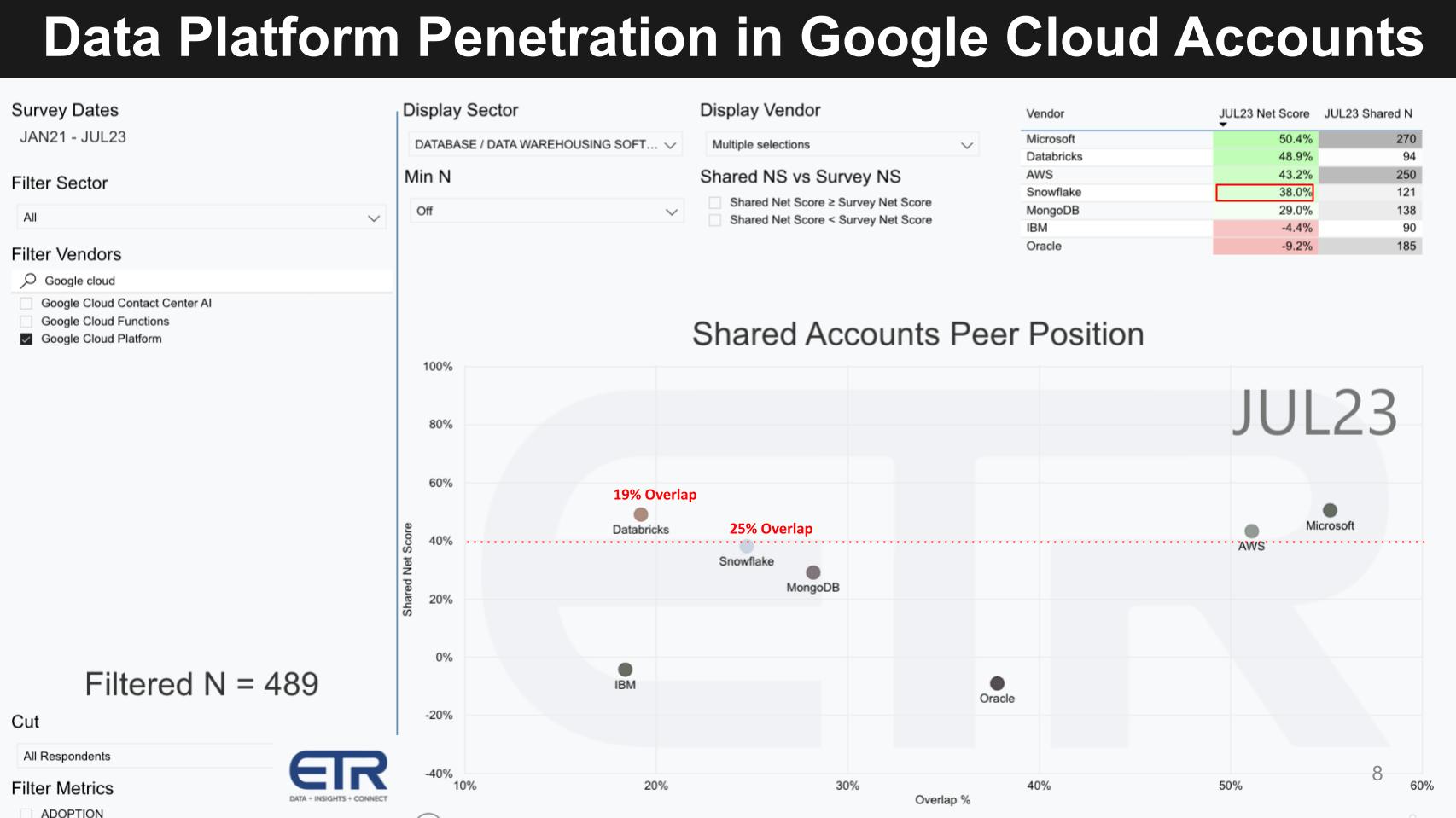
We believe this is a direct result of Google’s more competitive offerings.
Scarpelli on Google
Further evidence of this trend can be seen in the statements made by Scarpelli in June, shown below.

Google’s aspirations in data will be highlighted at Cloud Next
Google is a formidable data competitor. It uses the phrase “Data Cloud” in its marketing. It has a comprehensive platform, deep capabilities, significant AI capabilities and a strong roadmap which we believe it will unveil at the upcoming Google Next event.
In the following section, we go deep into how we see Google’s platform evolving and what to expect at Google Next.
What will data applications look like on Google Cloud?
Hyperscalers, as part of continually trying to expand their market, are trying to simplify and democratize the ability to build and run apps, which are increasingly data apps. To do that they’re trying to remove the development and operational complexity. They’re trying to shrink the gap between the complexity and power of an infrastructure as a service, or IaaS, and the simplicity but relative restrictiveness of platform as a service, or PaaS. To elaborate on the point about IaaS looking more like PaaS, we think that the big unveil at Google Cloud Next will be pervasive use of generative AI, as a code generator, to help shrink the complexity gap between IaaS and PaaS.
We think that all three cloud platforms are doing it. We suspect Microsoft was furthest along, because they started showing GitHub Copilot two years ago, and then Google was next most aggressive because they’ve been serious about generative AI from a research perspective even longer. And then AWS said they got serious about gen AI around eight to 10 months ago.
Regarding cloud apps becoming data apps, we’re moving from a world where users typed into a forms-based user interface to a world where data is being automatically collected or instrumented from people, places, things and activities. That data drives intelligent data apps, and that’s why Snowflake and Databricks are the real competition for the hyperscalers.
The last point to make is a specific prediction about what we think Google will show next week. We think Looker is likely to be the UI or presentation layer that integrates all these data application services.
How do the layers of IaaS map to PaaS?
In some ways, despite new services to make cloud development and operation easier, the cloud used to be a lot simpler when it was just Amazon’s EC2 and S3. Now there are hundreds and hundreds of services. Some are cross-cloud. There is the shared responsibility security model. Let’s focus in on how these IaaS services “map” to PaaS. And is there a simplification opportunity here?
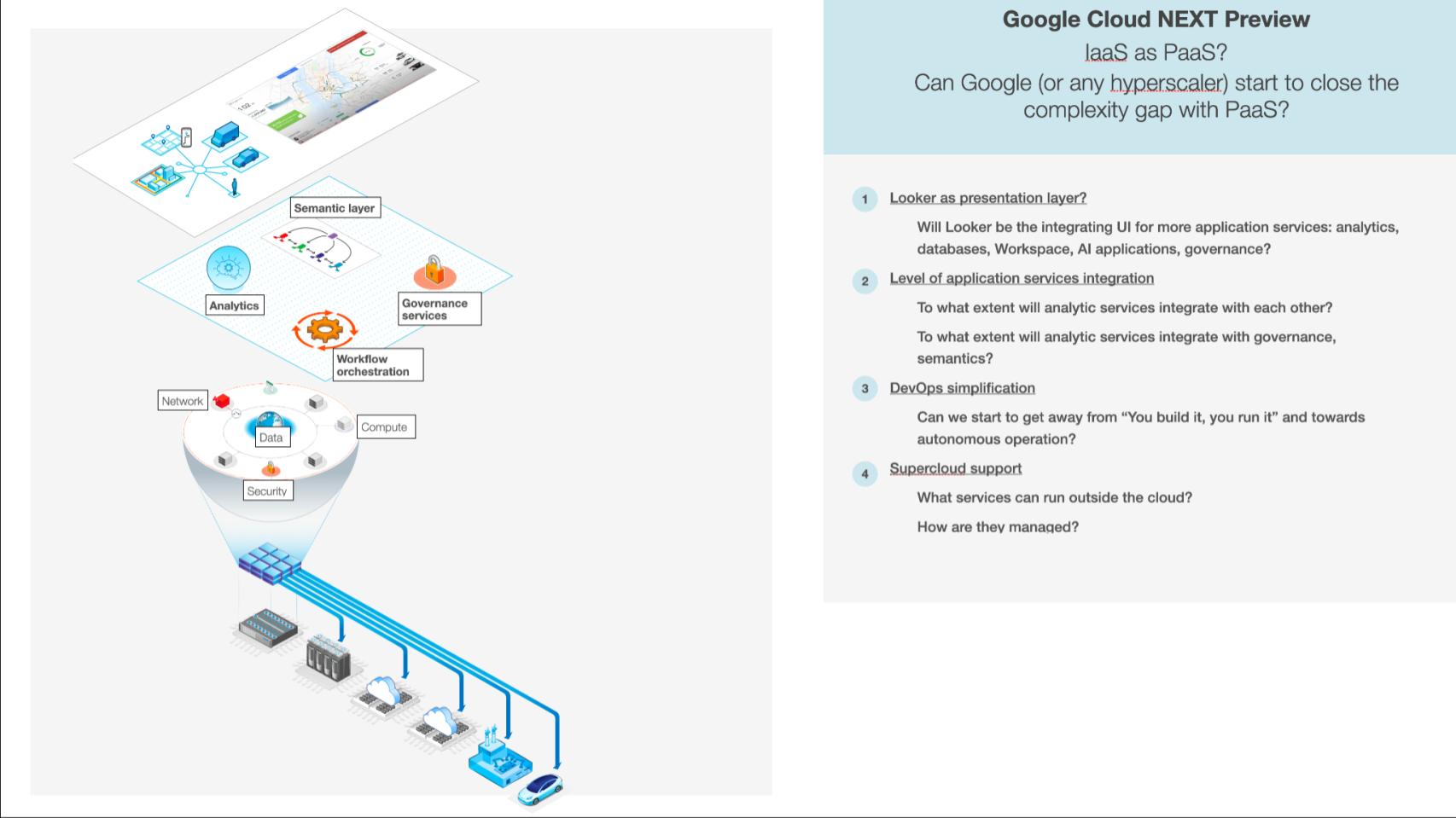
In some ways, despite new services to make cloud development and operation easier, the cloud used to be a lot simpler when it was just EC2 and S3. Now there are hundreds and hundreds of services. Some are cross cloud. There is the shared responsibility security model. Let’s focus in on how these IaaS services “map” to PaaS. And is there a simplification opportunity here?
We talked about Looker as the presentation layer. Can it use that UI to integrate all the application services such as analytics, AI, apps, databases and governance? Then there’s essentially three layers below that, which we’ll drill down into. This is the part gen AI can start to make IaaS look a bit more like PaaS. RedMonk was the first analyst firm to point out the potential for gen AI to accelerate this process. So the three layers would be:
- Application services integration: Can you integrate the app services with each other, and can they integrate with governance and semantics?
- DevOps simplification: This is the hardest one because that’s the real Achilles heel of an infrastructure as a service. There’s so much code that goes into deploying, running, monitoring and remediating when things go wrong. And that whole layer is taken care of for you in a PaaS. So that’s the big Achilles heel.
- Hybrid multicloud: Can it turn cloud from a location, which is the data centers that Google operates, into a supercloud. Supercloud is an operating model that runs software wherever, out on the edge, in private data centers and in smart devices. It uses a common control plane, essentially the cloud operating system, that runs everything for you.
Bringing application services together
How will Google attempt to fit the application services together and what will that look like?
There are several layers shown below, but the first one, we think, and it’s a question as to how much they’ll be able to show next week, but Google hinted at Duet AI as being the sort of its equivalent of Microsoft’s GitHub Copilot, the coding copilot, that would be on every programming surface in Google Cloud. That would allow it to generate a lot of the glue code that would simplify composing and integrating a lot of the services that you would use to build data apps. So a big question is: How much code can it generate? A related question is: How well-integrated are those analytics services so that they fit together without chewing gum and baling wire?
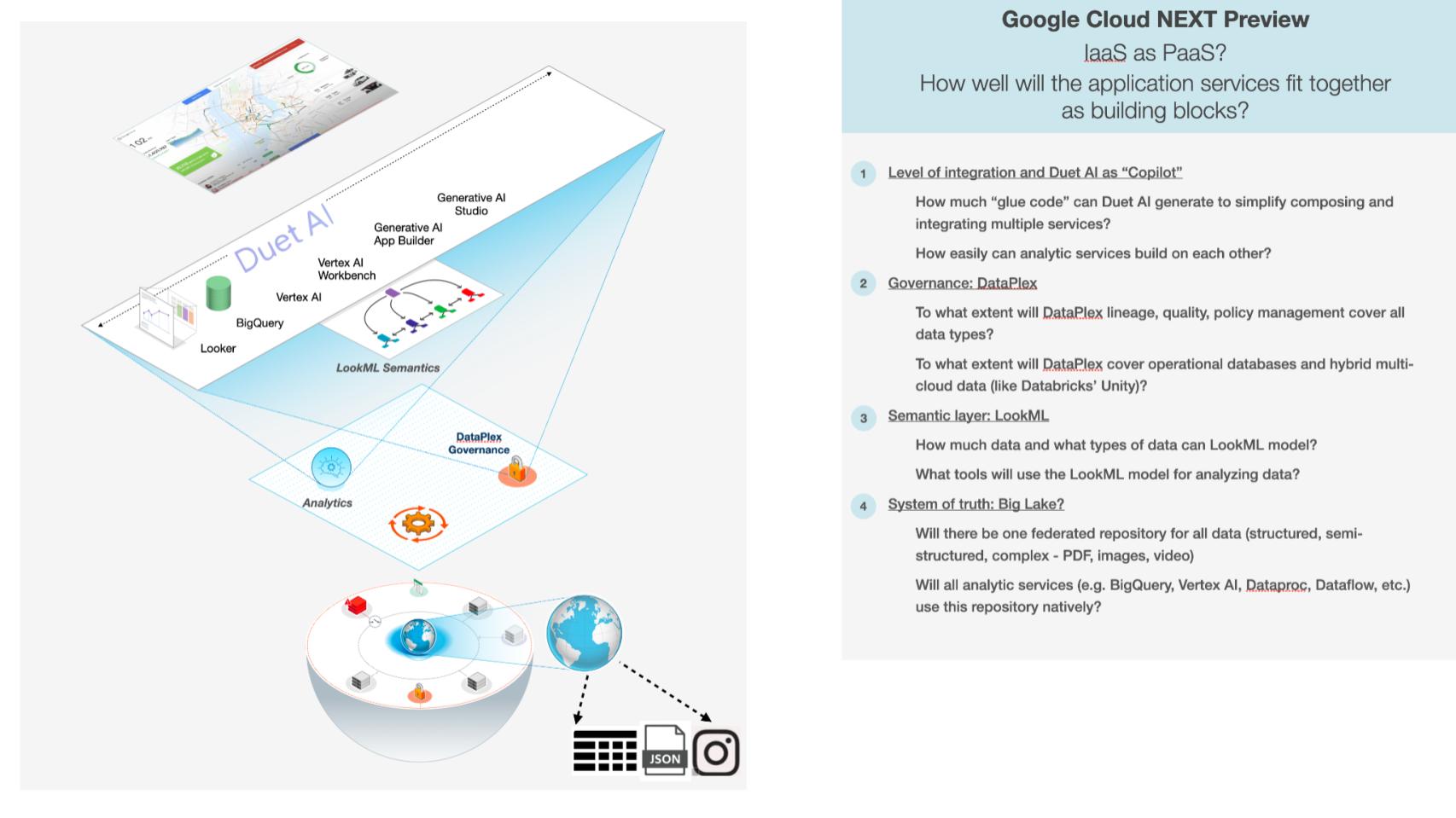
Then the second issue is governance. Now that we are living in a data-centric world, you want common governance across everything, independent of what service uses it. Dataplex is its service that has, so far, lineage, quality and policy management. But can it cover all data types wherever they exist? And will that eventually cover the operational databases? Will it cover hybrid multicloud data, like Databricks’ Unity aspires to?
And then there’s the semantic layer. This is where you take technical metadata that says what tables and columns are there, and you up-level it. Semantics defines what the data means in business terms, for example what are bookings, billings and revenue. Those are definitions that don’t really exist at the technical data level. So the question is: What tools will be able to use the LookML semantic model for analyzing data? Can that semantic model work across all data, not just business intelligence metrics? How far can it extend that?
And then lastly, the data itself: Will there be one system of truth? It doesn’t mean it has to all exist in one place. It could be one federated repository. I guess the technical term might be “one namespace” for all data — structured, semistructured, complex data, such as PDFs, images and video, where all the services work on just that repository of all the data. So not just BigQuery, but like Vertex AI, the big data services, streaming data services. Those are the key questions we’re looking to see answers to.
That’s an ambitious data stack, but that’s their direction. Bob Muglia, the former CEO of Snowflake, said that if Amazon built BigQuery, Snowflake would be a much smaller company. And that means the opportunity on Google Cloud platform is probably a lot smaller for Snowflake, because it have a great stack that is built around data. Redshift represented less competition because its codebase was originally designed as an on-premises product.
Simplifying DevOps and the IaaS stack and the role of AI
DevOps is the Achilles heel of IaaS. Let’s explore why, and how Google will evolve and simplify its stack for DevOps pros. As well, let’s address the role of AI.
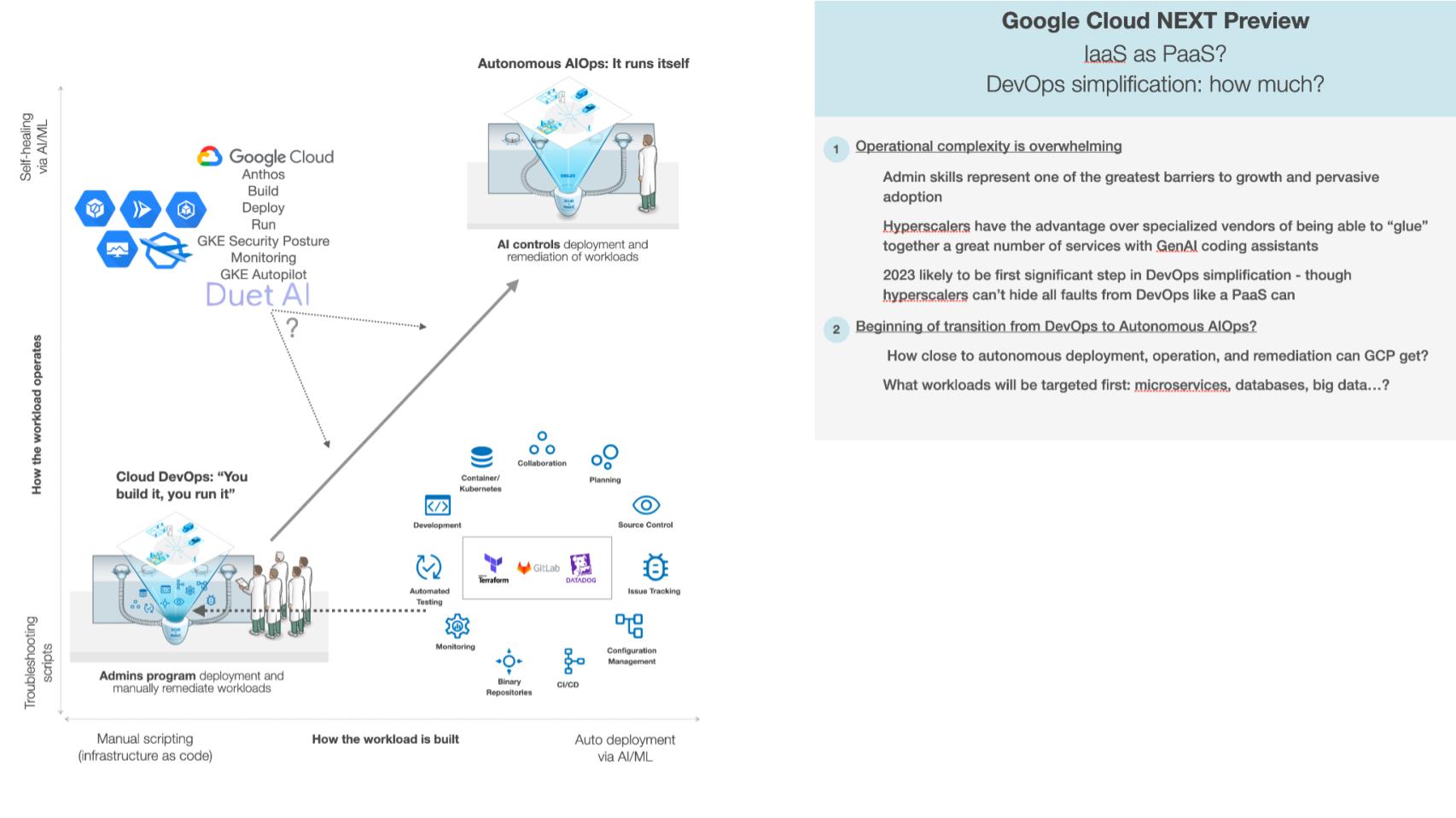
Now this is where Red Monk didn’t have much to say on IaaS looking more like PaaS. For years we have been moving from this DevOps model that Werner Vogels, Amazon’s chief technology officer, famously defined. The ethos in the cloud is, “You build it, you run it.” And if you look at this diagram in the lower left, it’s like that old Verizon commercial where someone’s moving around with a cell phone trying to get reception, and he’s got a hundred guys behind him. And he’s like, “Can you hear me now? Can you hear me now?”
The equivalent cloud version is, there’s a hundred DevOps professionals following you around when you build an app, trying to figure out, how are you going to deploy it, run it and remediate it when something goes wrong?
None of that exists when you’re using a PaaS. That’s why there’s a huge tax for using IaaS. However, if you have a coherent application model — which means, do your pieces fit together in an opinionated way? Are they designed to fit together? — that means you can build operational intelligence into AI that can understand when things go wrong. It knows how to diagnose problems, and, with high confidence, how to suggest remediation.
And you can set it so that if the confidence is high enough, it automatically remediates it. So the question is: How far along that spectrum can Google move next week, going from “you build it, you run it” to autonomous AIOps, where it runs itself?
Google announced and talked about a whole bunch of services built around Anthos, where Anthos then sits on Google Cloud Build, Deploy, Run, Monitor, and a whole bunch of diagnostic services. Can it build in enough intelligence to figure out when something goes wrong, how to remediate it, essentially to make DevOps engineers much more productive? In the diagram, that’s fewer guys in lab coats supporting your apps. That’s the critical thing to watch for.
This is a process. The AI has to get better over time at diagnosing and suggesting remediations. It’s both an accuracy issue and a trust issue. Over time DevOps engineers have to be comfortable letting it remediate problems autonomously.
Google and Microsoft have an advantage here because it built its services to be opinionated — which means it emphasized simplicity to a greater extent than AWS. Amazon built hundreds of services, many of which are overlapping for different use cases. Then it becomes much harder to stitch those together. So all three can do it, but Google and Microsoft should have an advantage in being able to understand how those services can fit together and simplify the DevOps. And let’s see how far Google can get on that spectrum.
What is Google’s supercloud play? Will it go there?
Snowflake was one of the first companies that we pointed to when we started thinking about this notion of supercloud. It’s a single global instance that spans not only multiple availability zones or regions within AWS, but multiple clouds. So that gives it the capability of both abstracting the underlying complexity, but also the potential of data sharing.
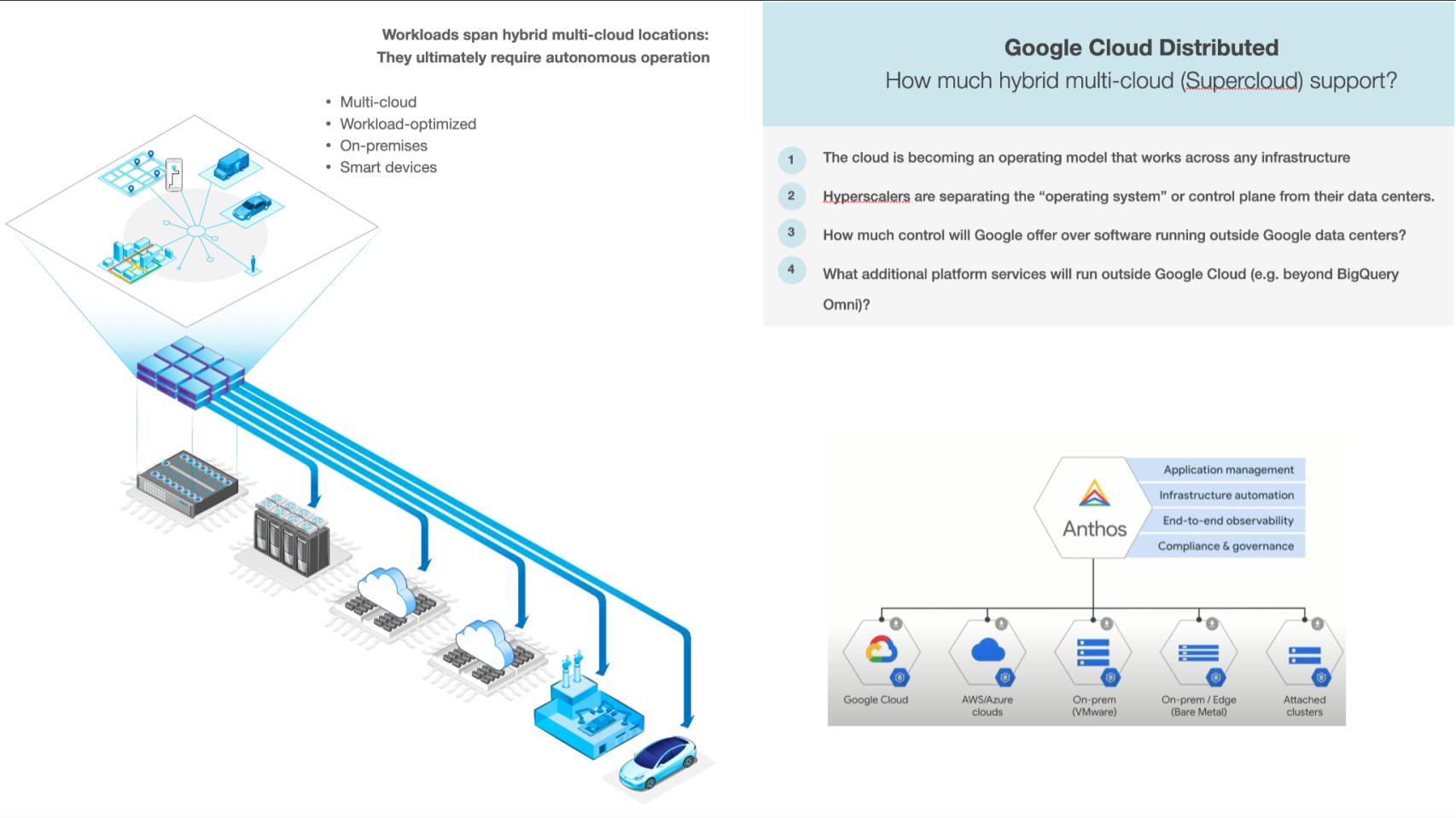
Snowflake announced the ability to apply Snowflake credits to any service on any cloud. That makes it more seamless to work with them if you’re running both AWS and Azure, which we see many customers doing, as we showed in the data. You can use Snowflake credits for anything in their marketplace across clouds not just one cloud. So that’s kind of interesting.
So what is Google’s supercloud play? Is it going to go there?
Google has been talking for a couple years now about starting to extend some of its application services such as BigQuery Omni, which runs on AWS and Azure, to run on other clouds.
It also talked about having some of its control plane, or the equivalent of the cloud operating system, run outside Google Cloud. So the goal here is having application services that run beyond the cloud, because your applications essentially are going to be running everywhere. You need a common control plane for those. So the question is: How much of the native Google Cloud control can you deploy on-prem, on the edge, like in a factory, or even on a device, where you can still control it from the cloud and then have that autonomous operation?
Anthos was a key part of this. It started, I think, as just stateless containers, which meant a very small subset of workloads. But it has been expanding that. So the question is: How many more workloads, how much control and how close is it to the type of control you get running in Google Cloud itself?
This is an opportunity for Google. We’ve covered it extensively. It’s in a distant third place, so it potentially has more motivation to build these cross-cloud services. We were just at VMware Explore this past week. That’s a huge thrust of VMware Inc., even as part of Broadcom Inc. Broadcom CEO Hock Tan has talked about that as a growth vector. So maybe Google can catch that wave as well and bring some added momentum to that platform. It seems, at least at this point in time, Amazon’s not interested in that, and I think perhaps Microsoft is a little bit more interested, but that’s really not their main thrust.
What to expect at Google Cloud Next 2023

Based on the discussions and insights shared, we believe the upcoming Google Cloud Next event will have several key areas of focus:
- Generative artificial intelligence: The prominence of Gen AI in the discussions implies that it will be a central theme. We anticipate discussions surrounding AI will permeate the event and Google will attempt to take the mindshare lead in the market, surpassing Microsoft’s OpenAI leverage.
- BigQuery and data cloud: Google’s BigQuery is a formidable cloud-native data platform. The platform is foundational to Google’s data cloud strategy. The evolution of new data applications, encompassing entities such as people, places and things, in a semantically coherent manner suggests Google has a unique vantage point in this domain.
- Mandiant integration: With the acquisition of Mandiant closed late last year, it is anticipated that security will play a pivotal role in the event’s narrative.
- Retail cloud focus: Insights from the Supercloud event session featuring Walmart Inc.’s Jack Greenfield hint at a distinct emphasis on the retail cloud. Google’s pursuit of clients such as Walmart, an Amazon competitor, suggests it’s likely to amplify conversations surrounding retail cloud solutions.
- Industry solutions and differentiation: With Thomas Kurian at the helm, Google Cloud has been striving for differentiation from competitors Microsoft and Amazon by emphasizing data solutions. It’s likely that a more comprehensive industry solutions approach is a strategic direction for Google Cloud.
Furthermore, attendees can expect engaging conversations from theCube, with hosts John Furrier, Lisa Martin, Rob Strechay and Dustin Kirkland presenting deep insights and extracting the signal from the noise.
Keep in touch
Many thanks to Alex Myerson and Ken Shifman on production, podcasts and media workflows for Breaking Analysis. Special thanks to Kristen Martin and Cheryl Knight, who help us keep our community informed and get the word out, and to Rob Hof, our editor in chief at SiliconANGLE.
Remember we publish each week on Wikibon and SiliconANGLE. These episodes are all available as podcasts wherever you listen.
Email david.vellante@siliconangle.com, DM @dvellante on Twitter and comment on our LinkedIn posts.
Also, check out this ETR Tutorial we created, which explains the spending methodology in more detail. Note: ETR is a separate company from Wikibon and SiliconANGLE. If you would like to cite or republish any of the company’s data, or inquire about its services, please contact ETR at legal@etr.ai.
Here’s the full video analysis:
[embed]https://www.youtube.com/watch?v=TIlWciemyS4[/embed]
All statements made regarding companies or securities are strictly beliefs, points of view and opinions held by SiliconANGLE Media, Enterprise Technology Research, other guests on theCUBE and guest writers. Such statements are not recommendations by these individuals to buy, sell or hold any security. The content presented does not constitute investment advice and should not be used as the basis for any investment decision. You and only you are responsible for your investment decisions.
Disclosure: Many of the companies cited in Breaking Analysis are sponsors of theCUBE and/or clients of Wikibon. None of these firms or other companies have any editorial control over or advanced viewing of what’s published in Breaking Analysis.
Image: Aryan/Adobe Stock
Your vote of support is important to us and it helps us keep the content FREE.
One-click below supports our mission to provide free, deep and relevant content.
Join our community on YouTube
Join the community that includes more than 15,000 #CubeAlumni experts, including Amazon.com CEO Andy Jassy, Dell Technologies founder and CEO Michael Dell, Intel CEO Pat Gelsinger and many more luminaries and experts.
THANK YOU




0 Comments