
Multiple machine learning applications, including text, vision, and audio, have seen rapid and significant developments in the technology of generative models. The industry and society have felt significant effects of these developments. Notably, generative models with multi-modal input have become a truly innovative development. Zero-shot text-to-speech (TTS) is a well-known speech generation problem in the speech domain that uses audio-text input. Using just a small audio clip of the intended talker, zero-shot TTS includes turning a text source into speech with that talker’s voice qualities and speaking manner. Fixed dimensional speaker embeddings were used in early research of zero-shot TTS. This method did not effectively support speaker cloning capabilities and restricted its use to TTS alone.
Recent strategies, however, have included broader concepts such as masked speech prediction and neural codec language modelling. These cutting-edge methods use the audio from the target speaker without compressing it into a one-dimensional representation. As a result, these models have displayed new features, such as voice conversion and speech editing, in addition to their exceptional zero-shot TTS performance. This increased adaptability can greatly expand the potential of speech-generating models. Despite their amazing accomplishments, these current generative models nevertheless have several limits, particularly when handling diverse audio-text-based speech-generating tasks that include converting input speech.
For example, current voice editing algorithms are limited to processing only clean signals and cannot change spoken content while maintaining background noise. Additionally, the approach discussed places major limitations on its practical applicability by requiring the noisy signal to be surrounded by clean speech segments to complete denoising. Target speaker extraction is a job that is particularly helpful in the context of changing unclean speech. Target speaker extraction is the process of removing a target speaker’s voice from a speech mixture that contains several talkers. You can specify the speaker you want by playing a little speech clip of them. As mentioned, the current generation of generative speech models cannot handle this job despite its potential importance.
Regression models have historically been used for reliable signal recovery in classical methods for speech enhancement tasks like denoising and target speaker extraction. However, these earlier techniques sometimes need different expert models for every job, which is not optimal given the variety of acoustic disruptions that may occur. Apart from small studies concentrating primarily on certain speech improvement tasks, much research has yet to be done on complete audio text-based speech enhancement models that use reference transcriptions to produce understandable speech. The development of audio-text-based generative speech models integrating generation and transformation capacities takes critical research relevance in light of the factors above and the successful precedents in other disciplines.
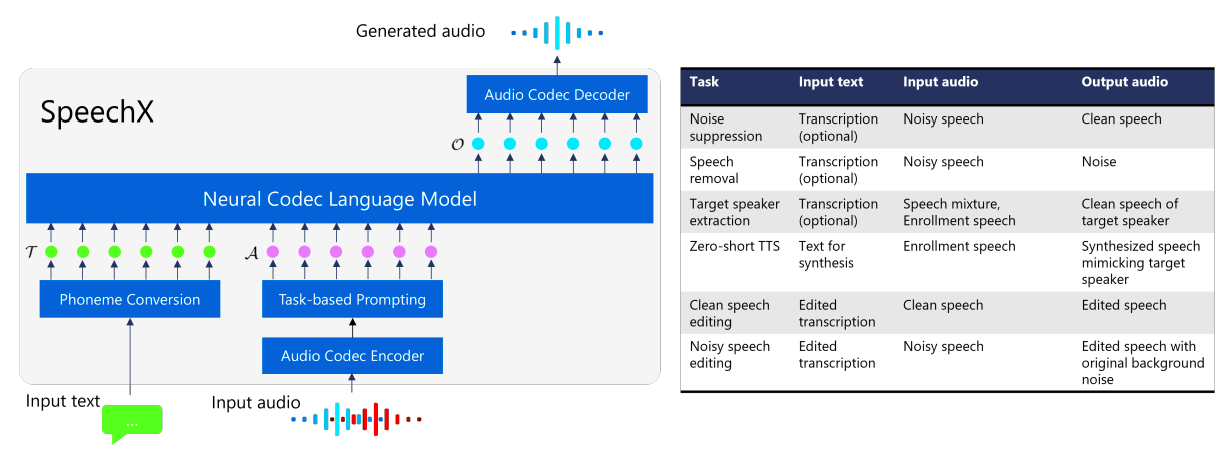
These models have the broad capacity to handle various voice-generating jobs. They suggest that such models should include the following crucial characteristics:
• Versatility: The unified audio-text-based generative speech models must be able to perform various tasks requiring voice generation from audio and text inputs, similar to unified or foundation models produced in other machine learning domains. Not just zero-shot TTS but also many types of speech alteration, including, for example, speech augmentation and speech editing, should be included in these activities.
• Tolerance: Since unified models are likely to be used in acoustically difficult contexts, they must demonstrate tolerance to diverse acoustic distortions. These models can be useful in real-world situations where background noise is common since they provide dependable performance.
• Extensibility: Flexible architectures must be used by the unified models to enable smooth task support expansions. One way to do this is to provide room for new components, such as extra modules or input tokens. The models will be better able to adapt to new speech-generating jobs because of this flexibility efficiently. Researchers from Microsoft Corporation in this paper introduce a flexible speech generation model to achieve this goal. It is capable of performing multiple tasks, such as zero-shot TTS, noise suppression using an optional transcript input, speech removal, target speaker extraction using an optional transcript input, and speech editing for both quiet and noisy acoustic environments (Fig. 1). They designate SpeechX1 as their recommended model.
As with VALL-E, SpeechX adopts a language modeling approach that generates codes of a neural codec model, or acoustic tokens, based on textual and acoustic inputs. To enable the handling of diverse tasks, they incorporate additional tokens in a multi-task learning setup, where the tokens collectively specify the task to be executed. Experimental results, using 60K hours of speech data from LibriLight as a training set, demonstrate the efficacy of SpeechX, showcasing comparable or superior performance compared to expert models in all the tasks above. Notably, SpeechX exhibits novel or expanded capabilities, such as preserving background sounds during speech editing and leveraging reference transcriptions for noise suppression and target speaker extraction. Audio samples showcasing the capabilities of their proposed SpeechX model are available at https://aka.ms/speechx.
Check out the Paper and Project Page. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 28k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.




0 Comments